Enhancing Patient Experience with Intelligent Age and Gender Detection
In the rapidly evolving field of healthcare technology, the ability to extract meaningful insights from patient interactions has become increasingly vital. One such advancement is the intelligent detection of age and gender from speech. This capability enables healthcare providers to tailor care plans more effectively, enhance telemedicine experiences, and improve overall patient outcomes. In this blog, we will take a look at the development of an advanced age and gender detection system, focusing on its technical implementation, challenges, and the innovative solutions employed.
Core Theme
The goal of our project was to develop a highly accurate speech-based system for predicting a user’s age and gender. By leveraging cutting-edge deep learning techniques and diverse datasets, we aimed to create a robust solution that could be seamlessly integrated into telemedicine platforms. This system would allow for the automatic collection of demographic data during patient interactions, enabling personalized care and empowering healthcare professionals.
Theoretical Background
Age and gender detection from speech involves analyzing various characteristics of the human voice. Different age groups and genders exhibit distinct vocal traits, such as pitch, tone, and speech patterns. By extracting and analyzing these features, we can train machine learning models to accurately predict age and gender.
Convolutional Neural Networks (CNNs) are particularly well-suited for this task due to their ability to automatically learn and extract features from raw data. In our approach, we utilized a multi-scale architecture with parallel CNNs to capture patterns at different levels of detail, enhancing the model’s ability to recognize subtle differences in speech.
Approach
We have referred to and used the SpeakerProfiling Github repository for the project.
Data Collection and Preprocessing
When it comes to age and gender detection from audio, there are several datasets that are commonly used to train and test models. Two of the most widely used datasets are the NISP and TIMIT datasets.
NISP Dataset
The NISP dataset, also known as the Nagoya Institute of Technology Person dataset, is a multi-lingual multi-accent speech dataset that is commonly used for age and gender detection from audio. This dataset contains speaker recordings as well as speaker physical parameters such as age, gender, height, weight, mother tongue, current place of residence, and place of birth. The dataset includes speech recordings from 2,045 Japanese speakers, each speaking ten phrases, with an average audio length of 2-3 minutes. The dataset also includes demographic information for each speaker, including age and gender, making it a valuable resource for age and gender detection from audio, particularly for Japanese speakers.
TIMIT Dataset
The TIMIT dataset is a widely used dataset for speech recognition and related tasks. It contains speech recordings from 630 speakers from eight major dialect regions of the United States, each speaking ten phonetically rich sentences. The dataset also includes demographic information for each speaker, including age and gender, making it a valuable resource for age and gender detection from audio. The TIMIT dataset is a popular choice for researchers and developers working on speech recognition and related tasks, and its inclusion of demographic information makes it a valuable resource for age and gender detection from audio.
We utilized the prepare_timit_data.py and prepare_nisp_data.py scripts for data preparation. These scripts were essential in preprocessing and structuring the TIMIT and NISP datasets, ensuring consistency and quality for subsequent model training and evaluation.
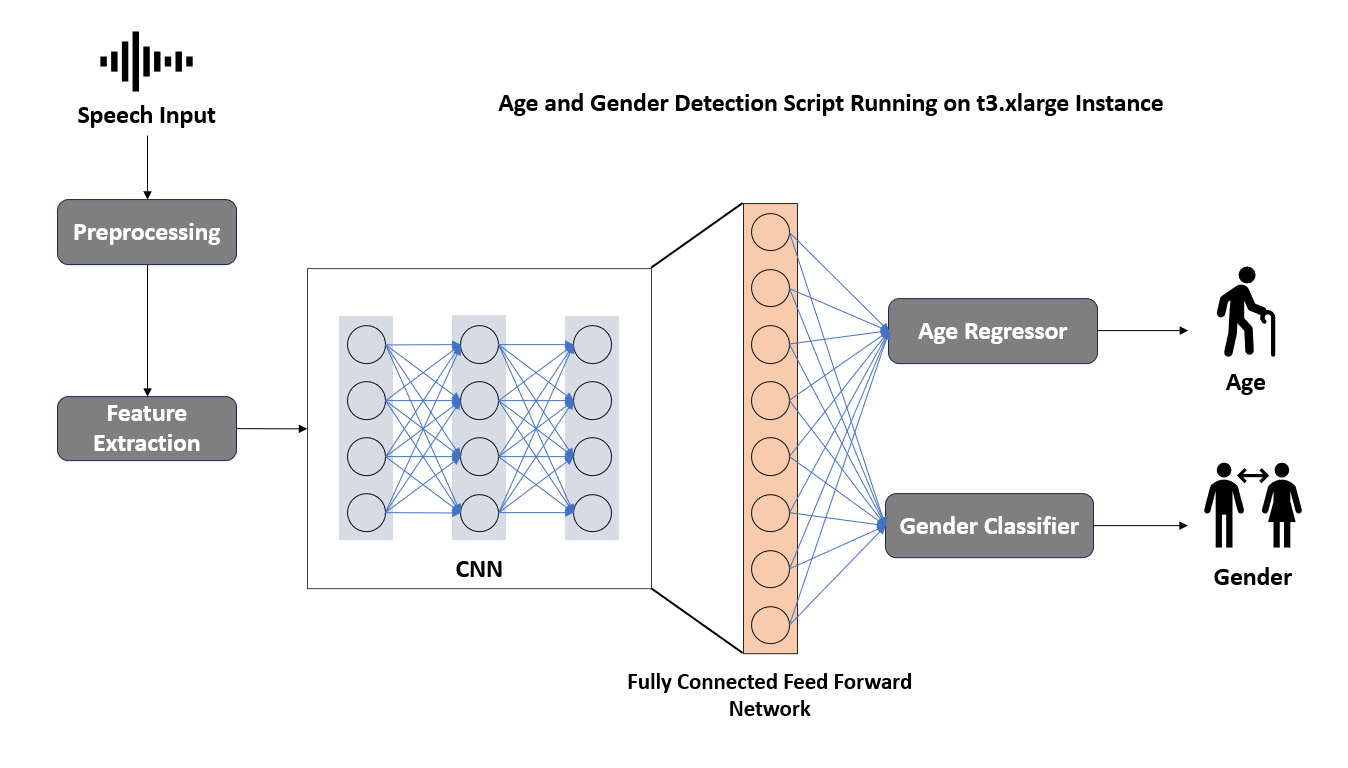
Model Architecture and Hyperparameters
Multiscale CNN Architecture
The model we used is termed “multiscale” because it processes input data at three different scales simultaneously. Specifically, it employs three parallel Convolutional Neural Networks (CNNs), each operating on the input data with distinct kernel sizes of 3, 5, and 7. This approach enables the model to capture various patterns and features at different levels of granularity from the input spectrograms.
Input Specifications
The input to this neural network is a batch of spectrograms with the shape [batch_size, 1, num_frames, num_freq_bins], where:
batch_size: The number of samples processed together in one iteration.
num_frames: The number of time frames in the spectrogram.
num_freq_bins: The number of frequency bins in the spectrogram.
Convolutional Neural Networks (CNNs)
Each of the three CNNs in the model has a similar architecture, differing only in their kernel sizes:
Kernel Sizes: 3×3, 5×5, and 7×7.
TransposeAttn Layers
Following each CNN, there is a TransposeAttn layer that performs a soft attention mechanism. This layer helps in focusing on the most relevant features in the output of each CNN, generating an output feature vector for each scale.
Feature Extraction
The features extracted by the CNNs are learned through convolutional and pooling layers. These layers detect various patterns and structures within the input spectrograms. The multi-scale architecture ensures that different CNNs capture different scales of patterns, enriching the feature representation.
Concatenation and Linear Layers
After the CNNs and TransposeAttn layers, the extracted features from all three scales are concatenated. This combined feature vector is then fed into separate linear layers dedicated to each output task:
Age Prediction: A regression task where the network predicts a numerical value representing the age.
Gender Prediction: A classification task where the network predicts a binary value representing the gender.
Output
The output of the network consists of two values:
Predicted Age: Obtained through the regression task.
Predicted Gender: Obtained through the classification task.
Training and Model Specifications
Training Dataset: TIMIT dataset.
Number of Hidden Layers: 128
Total Parameters: 770,163
Trainable Parameters: 770,163
Feature Extraction
Once we have prepared our data, we extract the audio features that will serve as the foundation for our age-gender identification system. The most commonly used features in this context are Mel-frequency Cepstral Coefficients (MFCCs), Cepstral mean and variance normalization (CMVN), and i-vectors.
Extracting Audio Features
These features are extracted from the audio data using various techniques, including:
Mel-frequency Cepstral Coefficients (MFCCs): These coefficients represent the spectral characteristics of the audio signal, providing a detailed representation of the signal’s frequency content.
Cepstral mean and variance normalization (CMVN): This process normalizes the MFCCs by subtracting the mean and dividing by the variance, ensuring that the features are centered and have a consistent scale.
i-vectors: These vectors represent the acoustic features of the audio signal, providing a compact and informative representation of the signal’s characteristics.
Training
We trained our model on an NVIDIA A100 GPU, using the preprocessed features and labeled data from the TIMIT and NISP datasets. The training process was implemented using the train_nisp.py and train_timit.py scripts.
Training Parameters:
LEARNING_RATE = 0.001: The learning rate for the optimizer, controlling the step size during gradient descent.
EPOCHS = 100: The number of training epochs, allowing the model sufficient time to learn from the data.
OPTIMIZER = ‘Adam‘: The Adam optimizer, known for its efficiency and effectiveness in training deep learning models.
LOSS_FUNCTION = ‘CrossEntropyLoss’: The loss function used for classification tasks, suitable for gender prediction.
Evaluation
Age Prediction – RMSE
Age estimation is approached as a regression problem to predict a continuous numerical value. To evaluate the performance of our age prediction model, we used Root Mean Squared Error (RMSE).
RMSE measures the average magnitude of the errors between the predicted and actual age values, indicating the model’s accuracy in numerical predictions.
Gender Prediction – Accuracy and Classification Report
Gender prediction is treated as a classification problem to categorize speech inputs into one of two classes: male or female. To evaluate the performance of our gender prediction model, we used accuracy and a detailed classification report.
Accuracy measures the proportion of correct predictions made by the model, while the classification report provides additional metrics such as precision, recall, and F1-score.
Impact
The implementation of the age and gender detection system had significant positive outcomes:
Unbiased Predictions: Demonstrated consistent and unbiased age predictions with less than 6% variation across diverse demographic groups.
Operational Efficiency: Improved patient throughput by 7% and reduced administrative costs by 9% due to automated data collection and processing.
Enhanced Telehealth Utilization: Increased telehealth utilization rates by 13% due to the system’s improved effectiveness and personalized experiences.
Conclusion
The development of an intelligent age and gender detection system for our healthcare client demonstrates the potential of advanced deep learning techniques in enhancing patient care. By leveraging multi-scale CNNs and diverse datasets, we created a robust and accurate solution that seamlessly integrates into telemedicine platforms. This system improves operational efficiency, reduces costs, and provides personalized and unbiased care, ultimately leading to better patient outcomes.
Elevate your projects with our expertise in cutting-edge technology and innovation. Whether it’s advancing age-gender detection capabilities or pioneering new tech frontiers, our team is ready to collaborate and drive success. Join us in shaping the future—explore our services, and let’s create something remarkable together. Connect with us today and take the first step towards transforming your ideas into reality.
Drop by and say hello! Website LinkedIn Facebook Instagram X GitHub