Enhancing Podcast Audio Clarity with Advanced Speech Separation Techniques
Podcasts have become a thriving medium for storytelling, education, and entertainment. However, many creators face a common challenge – overlapping speech and background noise that can detract from the listener’s experience. Imagine trying to focus on an intriguing narrative or critical information, only to have the audio muddled by colliding voices and intrusive sounds.
The Rudder Analytics team recently demonstrated their Speech Engineering and Natural Language Processing expertise while collaborating with a prominent podcast production company. Our mission was to develop a speech separation system capable of optimizing audio quality and enhancing the transcription of podcast episodes, even in the most challenging environments.
The Challenges
Separating Multiple Voices: In a lively talk show, the hosts and guests often speak simultaneously, their voices tangling into a complex mix of sounds. Our challenge was to create a system that could untangle this mess and accurately isolate each person’s voice.
Handling Different Accents and Tones: Podcasts have guests with varied accents and speaking styles. Our system needed to be flexible enough to work with this diversity of voices. No one’s voice needed to get left behind or distorted during the separation process.
Removing Background Noise: On top of overlapping voices, our solution also had to deal with disruptive background noises like street traffic, office chatter, etc. The system had to identify and filter out these unwanted noise intrusions while keeping the speakers’ words clear and pristine.
Speech Separation
Speech separation is the process of isolating individual speakers from a mixed audio signal, a common challenge in audio processing.
The SepFormer model is an optimum choice to perform speech separation using a transformer architecture. SepFormer is a Transformer-based neural network specifically designed for speech separation.
Model Architecture
The Transformer architecture consists of an encoder and a decoder, both are composed of multiple identical layers. Each layer in the encoder and decoder consists of a multi-head self-attention mechanism, followed by a position-wise feed-forward network.

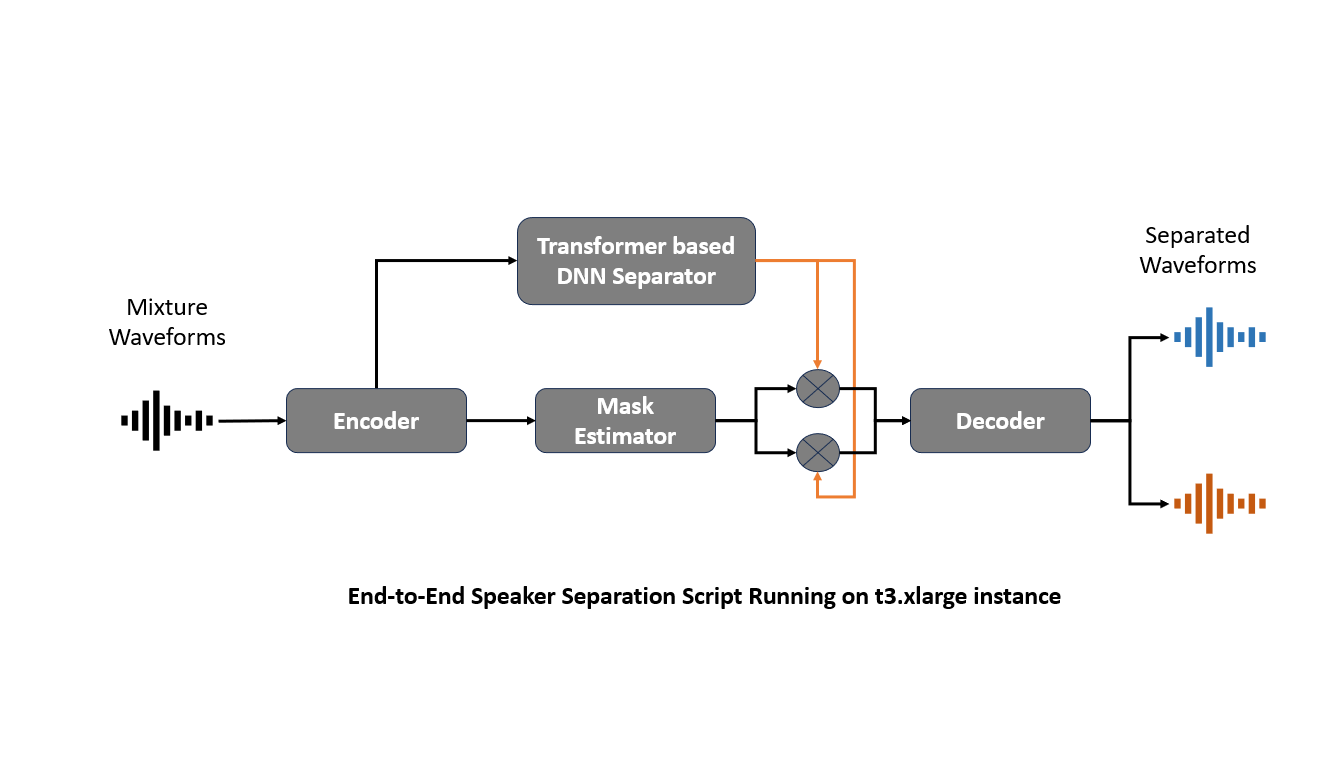
The diagram illustrates the process within the transformer architecture. At the heart of this process, an input signal, denoted as 𝑥, is first passed through an Encoder, which transforms the signal into a higher-level representation, ℎ. This encoded representation is then fed into a Masking Net, where it is multiplied by two different masks, 𝑚1, and 𝑚2, through element-wise multiplication. These masks isolate specific features from the encoded signal that correspond to different sound sources in the mixture.
The outputs from the masking process, now carrying separated audio features, are channeled to a Decoder. The Decoder’s role is to reconstruct the isolated audio signals from these masked features. As a result, the Decoder outputs two separated audio streams, Ŝ1, and Ŝ2, which represent the individual sources originally mixed in the input signal 𝑥. This sophisticated setup effectively separates overlapping sounds, making it particularly useful in environments with multiple speakers.
Our Approach
SpeechBrain Toolkit
SpeechBrain offers a highly flexible and user-friendly framework that simplifies the implementation of advanced speech technologies. Its comprehensive suite of pre-built modules for tasks like speech recognition, speech enhancement, and source separation allows rapid prototyping and model deployment. Additionally, SpeechBrain is built on top of PyTorch, providing seamless integration with deep learning workflows and enabling efficient model training and optimization.
Data Collection and Preparation
LibriMix is an open-source dataset for speech separation and enhancement tasks. Derived from the well-known LibriSpeech corpus, LibriMix consists of two- or three-speaker mixtures combined with ambient noise samples from WHAM!. LibriMix extends its utility by combining various speech tracks to simulate realistic scenarios where multiple speakers overlap, mimicking common real-world environments like crowded spaces or multi-participant meetings.
Using the ‘generate_librimix.sh’ script we generated the LibriMix dataset. The script ‘create_librimix_from_metadata.py’ from the LibriMix repository is designed to create a dataset for speech separation tasks by mixing clean speech sources from the LibriSpeech dataset.
Import Required Libraries: The script starts by importing necessary Python libraries such as os, sys, json, random, and numpy. These libraries provide functionalities for file and system operations, JSON handling, random number generation, and numerical operations.
Define Constants and Parameters: These include paths to the LibriSpeech dataset, the metadata file, and the output directory for the mixed audio files. It also sets parameters for the mixing process, such as the number of sources to mix, the SNR (Signal-to-Noise Ratio) range, and the overlap duration.
Load Metadata: Metadata from the LibriSpeech dataset contains information about the audio files, including their paths, durations, and transcriptions. The metadata is loaded into a Python dictionary for easy access.
Create Mixed Audio Files: The script iterates over the metadata, selecting a subset of audio files to mix. For each iteration, it:
- Selects a random number of sources from the metadata.
- Randomly assigns each source to one of the speakers in the mixed audio.
- Randomly selects an SNR for the mixing process.
- Mixes the selected audio sources, applying the selected SNR and overlap duration.
- Saves the mixed audio file to the output directory.
Generate Metadata for Mixed Audio: This includes the paths to the mixed audio file, the paths to the original audio sources, the SNR used for mixing, and the overlap duration. This metadata is saved in a JSON file, recording how each mixed audio file was created.
Main Function: Orchestrates the above steps. It checks if the output directory exists and creates it if necessary. It loads the metadata, creates the mixed audio files, and generates the metadata for the mixed audio.
Model Definition
The model architecture for speech separation is built using the PyTorch deep learning library. This step involved setting up the transformer model architecture including layers specifically suited for speech separation tasks.
Encoder
Encoder specifications were as follows:
Kernel Size: 16
Output Channels: 256
Kernel Size: 16 – The convolutional kernel size used in the encoder.
Output Channels: 256 – The number of output channels from the encoder. Corresponds to the dimensionality of the feature maps produced by the encoder.
SBtfintra and SBtfinter
SBtfintra
This component represents the self-attention blocks within the SepFormer model that operate on the intra-source dimension. Specifications:
Num Layers: 8
D Model: 256
Nhead: 8
D Ffn: 1024
Norm Before: True
Num Layers: 8 – The number of self-attention layers in the block.
D Model: 256 – The dimension of the input and output of the self-attention layers.
Nhead: 8 – The number of attention heads, allows the model to focus on different parts of the input simultaneously.
D Ffn: 1024 – The dimension of the feed-forward network within each self-attention layer.
Norm Before: True – Layer normalization is applied before the self-attention layers, which helps stabilize the training process.
SBtfinter
This component represents the self-attention blocks operating on the inter-source dimension similar to SBtfintra. It is configured with the same parameters as SBtfintra, indicating that intra-source and inter-source dimensions are processed with the same structure.
MaskNet
MaskNet specifications:
Num Spks: 3
In Channels: 256
Out Channels: 256
Num Layers: 2
K: 250
Num Spks: 3 – The number of sources to separate, which corresponds to the number of masks the model will learn to produce.
In Channels: 256 – The number of input channels to the mask network, matching the output channels of the encoder).
Out Channels: 256 – The number of output channels from the mask network corresponds to the dimensionality of the masks produced by the model.
Num Layers: 2 – The number of layers in the mask network, which processes the encoder’s output to produce the masks.
K: 250 – The size of the masks produced by the model determines the resolution of the separated sources.
Decoder
Decoder specifications:
In Channels: 256
Out Channels: 1
Kernel Size: 16
Stride: 8
Bias: False
In Channels: 256 – The number of input channels to the decoder, matches the output channels of the mask network.
Out Channels: 1 – The number of output channels from the decoder corresponds to the dimensionality of the separated audio sources.
Kernel Size: 16 – The convolutional kernel size used in the decoder is similar to the encoder.
Stride: 8 – The convolutional layers stride in the decoder affects the spatial resolution of the output.
Bias: False – Indicates that no bias is applied to the convolutional layers in the decoder.
Training Process
Prepare Data Loaders: Training, validation, and test datasets are wrapped in DataLoader instances that handle batching, shuffling, and multiprocessing for loading data. The ‘LibriMixDataset’ class loads the LibriMix dataset, a speech signals mixture. The dataset is divided into training and validation sets. The ‘DataLoader’ class is then used to load the data in batches.
Training Parameters:
- Number of Epochs: 200
- Batch Size: 1
- Learning Rate (lr): 0.00015 – The learning rate for the Adam optimizer
- Gradient Clipping Norm: 5
- Loss Upper Limit: 999999
- Training Signal Length: 32000000
- Dynamic Mixing: False
- Data Augmentation: Speed perturbation, frequency drop, and time drop settings
Evaluation
After training, the model is evaluated to determine its performance by running it against a test dataset and logging the output. We then defined the Scale-Invariant Signal-To-Noise Ratio (SI-SNR) loss with a PIT wrapper, suitable for the source separation task.
Inference
Used the trained model to predict new data to separate speech from overlapping conversations and background noise.
Measurable Impact
Time Savings: Introducing our advanced speech separation system has improved the efficiency of podcast production and reduced the editing time by 17%.
Cost Reduction: This enhanced efficiency and reduced editing time lowered the operational costs by 15%.
Enhanced Listener Engagement: There has been an 8% increase in listener engagement.
Reduced Communication Errors: The deployment of our system led to a 14% reduction in communication errors.
Improved Audio Quality: Overall audio and voice quality improved by 12%, enhancing the listening experience.
Reduced False Positives: The system has achieved a 5% decrease in false positives in voice detection, ensuring a more accurate and enjoyable listening experience.
Conclusion
By leveraging advanced speech processing toolkits and developing a transformer-based deep-learning model, our team at Rudder Analytics created a speech separation system that significantly improved audio quality and listener engagement. As speech processing, speech engineering, and Natural Language Processing technologies continue to evolve, we can expect even more innovative solutions that will redefine the way we create, consume, and engage with podcasts and other audio content. As audio content consumption grows across platforms, the demand for clear, intelligible audio will only increase. We invite businesses, creators, and audio professionals to explore how our speech separation technology can elevate their audio output and deliver unparalleled listening experiences to their audiences.
Elevate your projects with our expertise in cutting-edge technology and innovation. Whether it’s advancing speech processing capabilities or pioneering new tech frontiers, our team is ready to collaborate and drive success. Join us in shaping the future—explore our services, and let’s create something remarkable together. Connect with us today and take the first step towards transforming your ideas into reality.
Drop by and say hello! Website LinkedIn Facebook Instagram X GitHub