Optimizing Call Management with Advanced Voice Activity Detection Technologies
In today’s fast-paced digital landscape, contact centers need innovative solutions to enhance communication efficiency and customer satisfaction. One transformative technology at the forefront of this revolution is Voice Activity Detection (VAD). VAD systems are critical for distinguishing human speech from noise and other non-speech elements within audio streams, leveraging advanced speech engineering techniques. This capability is essential for optimizing agent productivity and improving call management strategies. Our comprehensive analysis explores how a leading contact center solution provider partnered with Rudder Analytics to integrate sophisticated VAD technology, driving significant advancements in outbound communication strategies.
VAD for Contact Centers
Voice activity detection (VAD) plays a pivotal role in enhancing the efficiency and effectiveness of contact center operations. In a contact center setting, VAD technology enables automatic detection of speech segments during customer-agent interactions, allowing for precise identification of when a caller is speaking or listening. By distinguishing between speech and silence accurately, VAD helps optimize call routing, call recording, and quality monitoring processes. For instance, VAD can trigger actions such as routing calls to available agents when speech is detected, pausing call recording during silent periods to comply with privacy regulations, or analyzing call quality based on speech activity levels. This streamlines call handling procedures and improves customer service by ensuring prompt and accurate responses, ultimately enhancing customer satisfaction and operational efficiency in contact center environments.
Critical Challenges
Environmental Variability: Contact centers encounter a wide variety of audio inputs, which include background noises, music, and varying speaker characteristics. Such diversity in audio conditions poses significant challenges to the VAD’s ability to consistently and accurately detect human speech across different environments.
Real-Time Processing Requirements: The dynamic nature of audio streams in contact centers demands that the VAD system operates with minimal latency. Delays in detecting voice activity can lead to inefficiencies in call handling, adversely affecting both customer experience and operational efficiency.
Integration with Existing Infrastructure: Implementing a new VAD system within the established telecommunication infrastructure of a contact center requires careful integration that does not disrupt ongoing operations. This challenge involves ensuring compatibility and synchronicity with existing systems.
Our Structured Approach
SpeechBrain Toolkit
We started with the SpeechBrain toolkit, which is an open-source speech processing toolkit. This toolkit provides a range of functionalities and recipes for developing speech-related applications.
Data Collection and Preparation
Collecting and preparing high-quality datasets is crucial for training effective VAD models. We gathered datasets such as LibriParty, CommonLanguage, Musan, and open-rir.
LibriParty: For training on multi-speaker scenarios commonly found in contact center environments.
CommonLanguage and Musan: To expose the model to a variety of linguistic content and background noises, respectively, ensuring the system’s robustness across different acoustic settings.
Open-rir: To include real impulse responses, simulating different spatial characteristics of sound propagation.
We used the ‘prepare_data.py’ script to preprocess and organize these datasets for the VAD system.
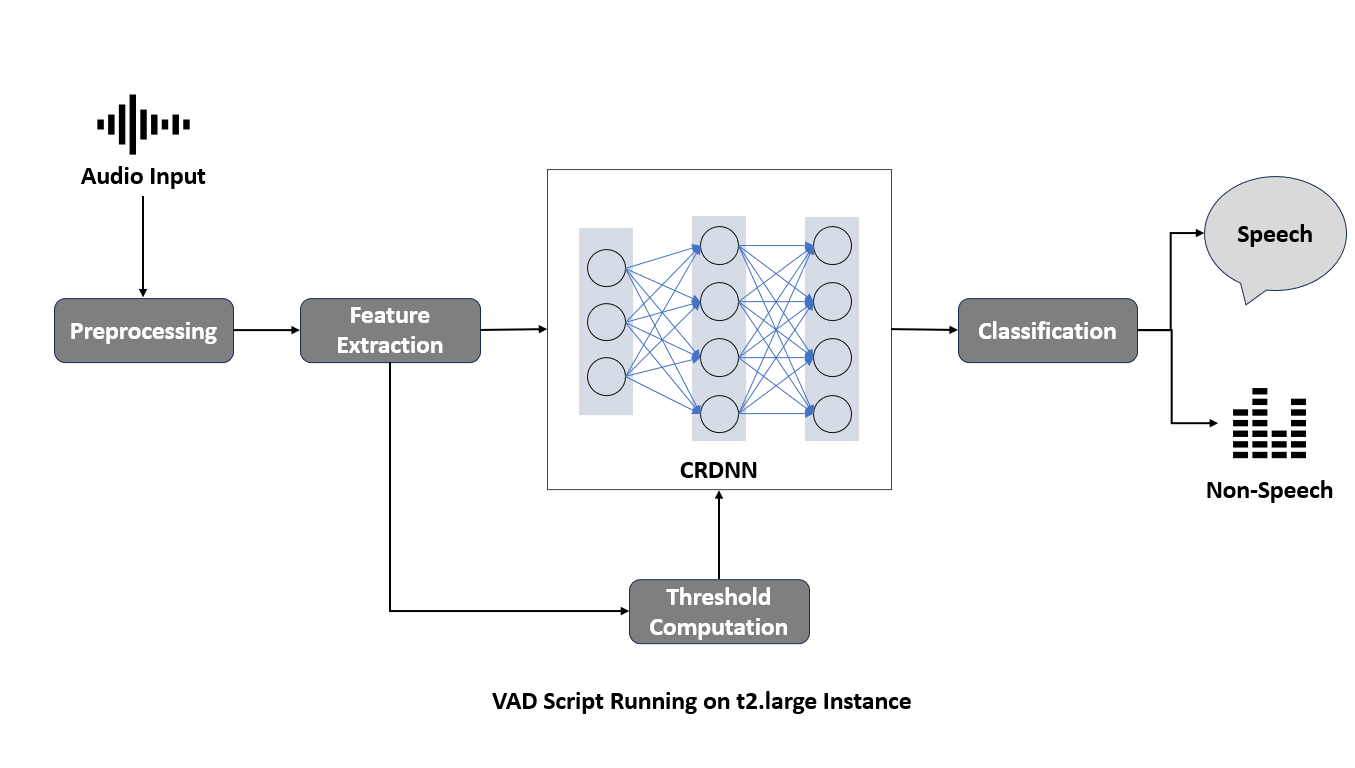
Model Design
For the VAD task, we designed a Deep Neural Network (DNN) model based on the LibriParty recipe provided by SpeechBrain.The LibriParty recipe offers a well-structured approach to building DNN models for speech-related tasks, ensuring efficient model development.
We created a ‘DNNModel’ class to encapsulate the DNN architecture and associated methods.
The model architecture is based on a ConformerEncoder, which has the following key parameters:
- ‘num_layers’: 17
- ‘d_model’: 144
- ‘nhead’: 8
- ‘d_ffn’: 1152
- ‘kernel_size’: 31
- ‘bias’: True
- ‘use_positional_encoding’: True
These parameters define the depth, representation dimensionality, number of attention heads, feedforward network dimensionality, kernel size, and usage of bias and positional encoding in the ConformerEncoder model.
‘input_shape: [40, None]’: indicating that the model expects 40-dimensional feature vectors of variable length.
The model also employs dual-path processing, with an intra-model path that processes data within chunks and an inter-model path that processes data across chunks.
The computation block consists of a DPTNetBlock, having parameters such as ‘d_model’, ‘nhead’, ‘dim_feedforward’, and ‘dropout’ controlling its behavior.
Positional encoding is used to capture positional information in the input data, which is crucial for speech-processing tasks
Feature Extraction
To provide a compact representation of the spectral characteristics of the audio signal, we computed standard FBANK (Filterbank Energy) features.
We used the script ‘compute_fbank_features.py’ to extract these features from the audio data.
FBANK features capture the essential information needed for accurate speech/non-speech classification.
Model Training
We trained the DNN model on an NVIDIA A10 GPU using the training set to leverage its computational power and accelerate the training process.
We used a script named ‘train_model.py’ to handle the training pipeline, which includes data loading, model forward pass, and loss computation.
We tuned the hyperparameters based on the validation set using a separate script called ‘optimize_hyperparameters.py’ to optimize the model’s performance.
Binary Classification
We performed binary classification to predict whether each input frame represents speech or non-speech during training.
We used the script ‘classify_frames.py’ to handle the classification task, which takes the DNN model’s output and assigns a speech/non-speech label to each frame.
This binary classification approach allows the VAD system to detect the presence of speech in the audio signal accurately.
Model Evaluation
To ensure the VAD model’s generalization capabilities, we evaluated it on a separate test set using the script ‘evaluate_model.py’.
We computed various evaluation metrics, such as accuracy, precision, recall, and F1-score, to assess the model’s performance on unseen data.
Evaluating the model on a test set helps validate its effectiveness in real-world scenarios and identifies potential areas for improvement.
Impactful Results and Business Benefits
- High Accuracy: Achieved an accuracy rate of 97% in identifying live human voices, significantly reducing false positives associated with non-human sounds.
- Reduced Latency: The system’s response time was optimized to an impressive 1.1 seconds, facilitating quicker and more effective agent responses.
- Improved Connection Rates: With an 85% success rate in connecting calls to live recipients, the system minimized unnecessary agent wait times.
- Increased Agent Efficiency: Agents experienced a 33% increase in productivity, managing more calls per hour, which led to a 21% reduction in the cost-per-call—a direct reflection of heightened operational efficiency.
Wrapping Up
The successful deployment of this VAD system marks a significant milestone in voice technology application within contact centers. The potential for further advancements in machine learning and speech processing is vast. Businesses that embrace these technologies can expect not only to enhance their operational efficiencies but also to significantly improve the quality of customer interactions, positioning themselves at the forefront of industry innovation.
Elevate your projects with our expertise in cutting-edge technology and innovation. Whether it’s advancing voice detection capabilities or pioneering new tech frontiers, our team is ready to collaborate and drive success. Join us in shaping the future—explore our services, and let’s create something remarkable together. Connect with us today and take the first step towards transforming your ideas into reality.
Drop by and say hello! Website LinkedIn Facebook Instagram X GitHub