Streamlining Medical Transcription with Speaker Diarization
In the modern era of digital communication, the need for accurate and efficient transcription of conversations has become greatly important across various industries. However, manually transcribing lengthy conversations, particularly those involving multiple speakers, can be daunting, often plagued by errors, inefficiencies, and time-consuming processes. Enter speaker diarization technology, an innovative solution that promises to transform how we approach conversation transcription.
Understanding Speaker Diarization
Speaker diarization is an advanced technology that aims to identify and label different speakers in an audio recording automatically. Unlike traditional transcription methods, speaker diarization goes beyond mere text conversion by providing speaker-specific information, such as the start and end times for each speaker’s utterances. This technology is precious in scenarios involving multiple speakers, such as meetings, interviews, legal proceedings, or medical procedures.
Speaker diarization relies on sophisticated algorithms and machine learning techniques to analyze the audio stream, detect speaker changes, and associate each speech segment with a unique speaker label. By doing so, it enables accurate and comprehensive transcription, ensuring that every word spoken is accurately attributed to the correct speaker.
Optimizing Operating Room Transcription
In the healthcare domain, accurate and comprehensive medical documentation is of utmost importance, as it directly impacts the quality of patient care and safety. Our client, a leading provider of surgical services, recognized the immense potential of speaker diarization technology in optimizing operating room transcription processes.
Before implementing our solution, the client faced significant challenges in accurately transcribing surgical procedures, where multiple healthcare professionals communicate simultaneously during the operation. Manual transcription was not only time-consuming but also prone to errors, hindering post-operative analysis and potentially compromising the integrity of medical records.
Understanding the Challenge
Developing an effective speaker diarization system for conversation transcription presented several complex challenges, including:
Speaker Identification: The system needed to accurately identify and differentiate between multiple speakers, such as surgeons, nurses, and anesthesiologists, even in the acoustically challenging environment of an operating room.
Dynamic Acoustic Conditions: Surgical rooms are inherently noisy and filled with unexpected sounds, from medical equipment to overlapping conversations. The diarization system had to be resilient and adaptable to these conditions, ensuring consistent accuracy.
Temporal Precision: It was crucial for the system to not only recognize different speakers but also to precisely log the start and end times of each speaker’s contributions, providing a detailed and chronological account of the spoken dialogue.
Crafting the Solution
Developing an effective speaker diarization system that meets the intricate demands of surgical procedure transcriptions involves a comprehensive, multi-stage process. At the heart of our approach lies utilizing the Kaldi Automatic Speech Recognition (ASR) toolkit with its callhome recipe. We have used a Time-Delay Neural Network (TDNN) based x-vector model in our approach. Kaldi is celebrated for its versatility and strength in tackling a wide array of speech recognition tasks, making it an ideal choice for our ambitious project.
If you are interested in the codebase, check out our GitHub repository
Feed-Forward Deep Neural Network
At the core of our speaker diarization system lies a robust neural network architecture designed to extract speaker embeddings from variable-length acoustic segments. This feed-forward Deep Neural Network (DNN), illustrated in Figure 1 (source), employs a carefully crafted combination of layers to capture the intricate characteristics of speech signals.
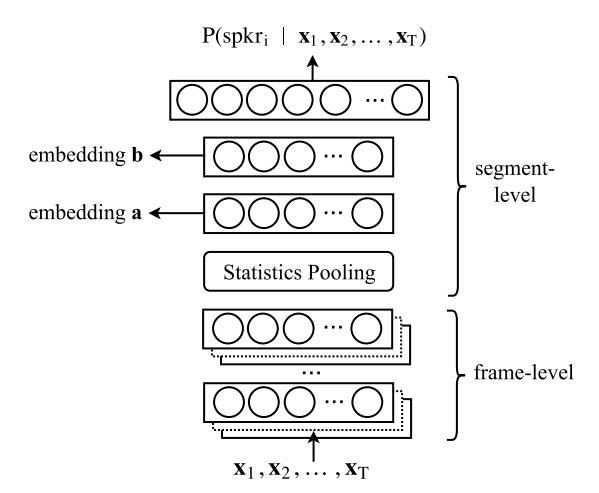
Feature Extraction
The neural network’s input consists of Mel-Frequency Cepstral Coefficient (MFCC) features, a widely adopted representation of the speech signal’s spectral characteristics. These features are extracted using a 20ms frame length and normalized over a 3-second window, ensuring consistent and robust feature representations.
Frame-Level Processing
The initial five layers of the network operate at the frame level, leveraging a time-delay architecture to model short-term temporal dependencies effectively. Unlike traditional stacked frame inputs, this architecture seamlessly incorporates temporal context by design, enhancing the network’s ability to capture the intricate dynamics of speech signals.
Statistics Pooling
The network’s statistics pooling layer is pivotal in condensing the frame-level representations into segment-level statistics. By aggregating the output of the final frame-level layer, this layer computes the mean and standard deviation of the input segment, encapsulating its essential characteristics.
Segment-Level Processing
The segment-level statistics, comprising the mean and standard deviation, are concatenated and passed through two additional hidden layers. These layers further refine and enrich the extracted representations, preparing them for the final speaker embedding generation.
Output Layer
The softmax output layer serves as the culmination of the network’s processing pipeline. It receives the refined segment-level representations and generates the final speaker embeddings, which encapsulate the distinguishing characteristics of each speaker.
Architectural Dimensions
Excluding the softmax output layer, the neural network boasts a substantial 4.4 million parameters, enabling it to capture intricate patterns and nuances within the speech data.
Diarization Process in Kaldi
After designing the model architecture and training the model using callhome recipe, we started the speaker diarization process in Kaldi.
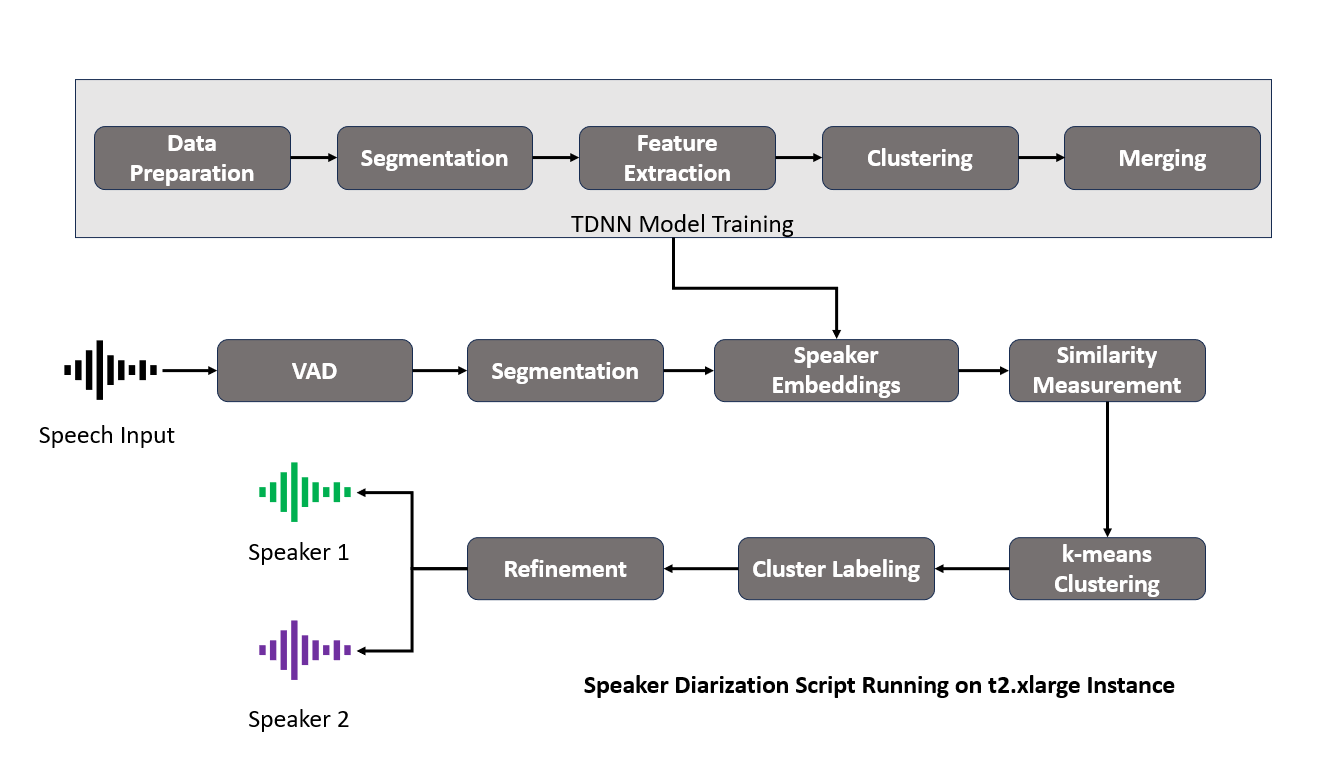
Step 1: Data Preparation
We began by organizing our audio data for Kaldi’s processing. This involves creating two essential files: the wav.scp, which maps each audio file to its location, and the spk2utt file which maps the speaker to the utterance.
Step 2: Feature Extraction
For feature extraction, we used Kaldi’s make_mfcc.sh and prepare_feats.sh scripts. Employing Mel Frequency Cepstral Coefficients (MFCCs) and Cepstral Mean and Variance Normalization (CMVN), we captured the unique acoustic signatures of each speaker, laying a robust foundation for the intricate process of speaker differentiation.
Step 3: Creating the Segments File
After feature extraction, the next step was to generate the segments file, detailing the start and end times of speech within the input file. The script: compute_vad_decision.sh was used to identify speech segments, crucial for accurate diarization.
Step 4: X-Vector Creation
With our features ready, we created x-vectors using the extract_xvectors.sh script from Kaldi. These vectors serve as compact representations of each speaker’s characteristics within the audio, essential for differentiating between speakers.
Step 5: PLDA Scoring
Next, we applied Probabilistic Linear Discriminant Analysis (PLDA) to score the similarity between pairs of x-vectors. PLDA scores were calculated using Kaldi’s score_plda.sh script. This statistical method helps in modeling the speaker-specific variability and is instrumental in the clustering phase, where speaker embeddings are categorized.
Step 6: Clustering
We then used the PLDA scores as a basis for clustering the x-vectors. cluster.sh script from Kaldi groups the vectors based on their similarity, effectively organizing the audio segments by speaker identity. The goal is to ensure that segments from the same speaker are grouped accurately.
Step 7: Refinement
After initial clustering, we employed PLDA again using cluster.sh script in a re-segmentation step to refine the diarization output. By assessing PLDA scores for shorter segments or frames, we could make detailed adjustments to speaker segment boundaries, enhancing the precision of the diarization results.
Finally, we combined the diarization results with the Automatic Speech Recognition system to generate the output.


Realizing the Impact
The implementation of this sophisticated speaker diarization system led to a notable improvement in the transcription process. With a Diarization Error Rate (DER) reduced to 4.3%, the system demonstrated remarkable accuracy in distinguishing between speakers. This advancement yielded significant operational efficiencies, notably a 40% reduction in the time required for post-operative review and analysis. Moreover, the integration of this technology into Electronic Health Record (EHR) systems resulted in a 30% decrease in data entry errors, ensuring more accurate and synchronized patient records.
Conclusion: The Intersection of AI and Healthcare
Rudder Analytics’ integration of speaker diarization in healthcare highlights our commitment to bridging sophisticated technology with practical needs. Our primary objective is to accurately capture and document every word spoken in the operating room, aiding in precise surgical transcriptions. This initiative is part of our broader mission to drive advancements in patient care. By harnessing the power of AI and data analytics, we aim to solve intricate challenges, underscoring our dedication to thoughtful innovation within the healthcare domain. Through this endeavor, we seek to showcase the pivotal role that advanced technologies can play in enhancing the quality of care provided to patients.
As technology continues to evolve, the applications of speaker diarization extend far beyond the healthcare industry. Businesses, legal firms, media organizations, and various other sectors can benefit from this technology, enabling accurate and efficient transcription of multi-speaker conversations, ultimately driving productivity, enhancing decision-making processes, and fostering better collaboration.
Elevate your projects with our expertise in cutting-edge technology and innovation. Whether it’s advancing transcription capabilities or pioneering in new tech frontiers, our team is ready to collaborate and drive success. Join us in shaping the future—explore our services, and let’s create something remarkable together. Connect with us today and take the first step towards transforming your ideas into reality.
Drop by and say hello! Medium LinkedIn Facebook Instagram X GitHub