Voice-Based Security: Implementing a Robust Speaker Verification System
In the evolving digital security landscape, traditional authentication methods such as passwords and PINs are becoming increasingly vulnerable to breaches. Voice-based authentication presents a promising alternative, leveraging unique vocal characteristics to verify user identity. Our client, a leading technology company specializing in secure access solutions, aimed to enhance their authentication system with an efficient speaker verification mechanism. This blog post outlines our journey in developing this advanced system, detailing the challenges faced and the technical solutions implemented.
Theoretical Background
What is Speaker Verification?
Speaker verification is a biometric authentication process that uses voice features to verify the identity of a speaker. It is a binary classification problem where the goal is to confirm whether a given speech sample belongs to a specific speaker or not. This process relies on unique vocal traits, including pitch, tone, accent, and speaking rate, making it a robust security measure.
Importance in Security
Voice-based verification adds an extra layer of security, making it difficult for unauthorized users to gain access. It is useful where additional authentication is needed, such as secure access to sensitive information or systems. The user-friendly nature of voice verification also enhances user experience, providing a seamless authentication process.
Client Requirements and Challenges
Ensuring Authenticity
The client’s primary requirement was a system that could authenticate and accurately distinguish between genuine users and potential impostors.
Handling Vocal Diversity
A significant challenge was designing a system that could handle a range of vocal characteristics, including different accents, pitches, and speaking paces. This required a robust solution capable of maintaining high verification accuracy across diverse user profiles.
Scalability
As the client anticipated growth in their user base, the system needed to be scalable. It was crucial to handle an increasing number of users without compromising performance or verification accuracy.
ECAPA-TDNN Model Architecture and Parameters
The ECAPA-TDNN (Emphasized Channel Attention, Propagation, and Aggregation Time Delay Neural Network) model architecture is a significant advancement in speaker verification systems. Designed to capture both local and global speech features, ECAPA-TDNN integrates several innovative techniques to enhance performance.
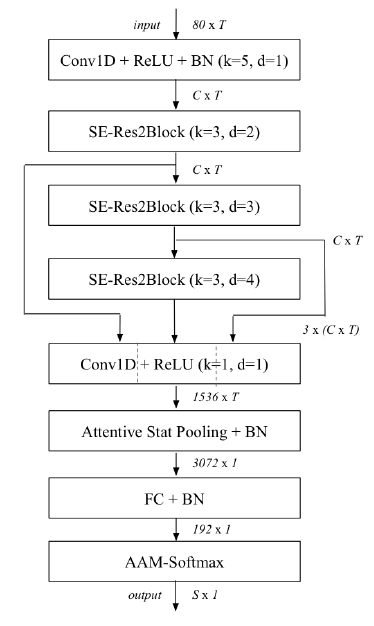
The architecture has the following components:
Convolutional Blocks: The model starts with a series of convolutional blocks, which extract low-level features from the input audio spectrogram. These blocks use 1D convolutions with kernel sizes of 3 and 5, followed by batch normalization and ReLU activation.
Residual Blocks: The convolutional blocks are followed by a series of residual blocks, which help to capture higher-level features and improve the model’s performance. Each residual block consists of two convolutional layers with a skip connection.
Attention Mechanism: The model uses an attentive statistical pooling layer to aggregate the frame-level features into a fixed-length speaker embedding. This attention mechanism helps the model focus on the most informative parts of the input audio.
Output Layer: The final speaker embedding is passed through a linear layer to produce the output logits, which are then used for speaker verification.
The key hyperparameters and parameter values used in the ECAPA-TDNN model are:
Input dimension: 80 (corresponding to the number of mel-frequency cepstral coefficients)
Number of convolutional blocks: 7
Number of residual blocks: 3
Number of attention heads: 4
Embedding dimension: 192
Dropout rate: 0.1
Additive Margin Softmax Loss
VoxCeleb2 Dataset
The VoxCeleb2 dataset is a large-scale audio-visual speaker recognition dataset collected from open-source media. It contains over a million utterances from over 6,000 speakers, several times larger than any publicly available speaker recognition dataset. The dataset is curated using a fully automated pipeline and includes various accents, ages, ethnicities, and languages. It is useful for applications such as speaker recognition, visual speech synthesis, speech separation, and cross-modal transfer from face to voice or vice versa.
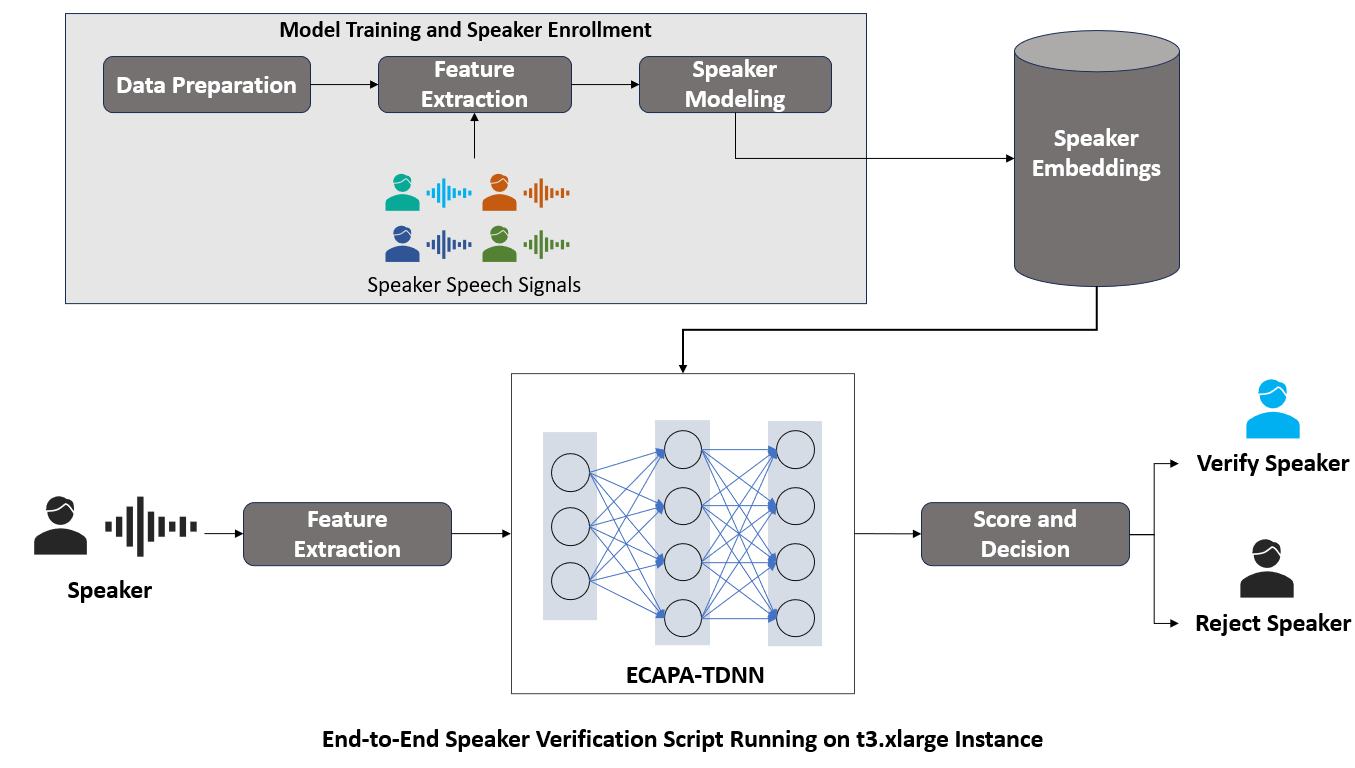
Implementing the Speaker Verification System
We have referred to and used the Speaker Verification Github repository for the project.
SpeechBrain Toolkit
SpeechBrain offers a highly flexible and user-friendly framework that simplifies the implementation of advanced speech technologies. Its comprehensive suite of pre-built modules for tasks like speech recognition, speech enhancement, and source separation allows rapid prototyping and model deployment. Additionally, SpeechBrain is built on top of PyTorch, providing seamless integration with deep learning workflows and enabling efficient model training and optimization.
Prepare the VoxCeleb2 Dataset
We used the ‘voxceleb_prepare.py’ script for preparing the VoxCeleb2 dataset. The voxceleb_prepare.py script is responsible for downloading the dataset, extracting the audio files, and creating the necessary CSV files for training and evaluation.
Feature Extraction
Before training the ECAPA-TDNN model, we needed to extract features from the VoxCeleb2 audio files. We utilized the extract_speaker_embeddings.py script with the extract_ecapa_tdnn.yaml configuration file for this task.
These tools enabled us to extract speaker embeddings from the audio files, which were then used as inputs for the ECAPA-TDNN model during the training process. This step was crucial for capturing the unique characteristics of each speaker’s voice, forming the foundation of our verification system.
Training the ECAPA-TDNN Model
With the VoxCeleb2 dataset prepared, we were ready to train the ECAPA-TDNN model. We fine-tuned the model using the train_ecapa_tdnn.yaml configuration file.
This file allowed us to specify the key hyperparameters and model architecture, including the input and output dimensions, the number of attention heads, the loss function, and the optimization parameters.
We trained the model using hyperparameter tuning and backpropagation, on an NVIDIA A100 GPU instance and achieved improved performance on the VoxCeleb benchmark.
Evaluating the Model’s Performance
Once the training was complete, we evaluated the model’s performance on the VoxCeleb2 test set. Using the eval.yaml configuration file, we were able to specify the path to the pre-trained model and the evaluation metrics we wanted to track, such as Equal Error Rate (EER) and minimum Detection Cost Function (minDCF).
We used the evaluate.py script and the eval.yaml configuration file to evaluate the ECAPA-TDNN model on the VoxCeleb2 test set.
The evaluation process gave us valuable insights into the strengths and weaknesses of our speaker verification system, allowing us to make informed decisions about further improvements and optimizations.
Impact and Results
Accuracy and Error Rates
Our system was successfully adapted to handle diverse voice data, achieving a 99.6% accuracy across various accents and languages. This high level of accuracy was crucial for providing reliable user authentication. Additionally, we achieved an Equal Error Rate (EER) of 2.5%, indicating the system’s strong ability to distinguish between genuine users and impostors.
Real-Time Processing
A significant achievement was reducing the inference time to 300 milliseconds per verification. This improvement allowed for real-time processing, ensuring seamless user authentication without delays.
Scalability
The system demonstrated remarkable scalability, handling a 115% increase in user enrollment without compromising verification accuracy. This scalability was critical in meeting the client’s future growth requirements.
Conclusion
Implementing a sophisticated speaker verification system using SpeechBrain and the VoxCeleb2 dataset was challenging yet rewarding. We developed a robust solution that enhances user security and provides a seamless authentication experience, by addressing vocal variability, scalability, and real-time processing. This project underscores the importance of combining advanced neural network architectures, comprehensive datasets, and meticulous model training to achieve high performance in real-world applications.
Elevate your projects with our expertise in cutting-edge technology and innovation. Whether it’s advancing speaker verification capabilities or pioneering new tech frontiers, our team is ready to collaborate and drive success. Join us in shaping the future—explore our services, and let’s create something remarkable together. Connect with us today and take the first step towards transforming your ideas into reality.
Drop by and say hello! Website LinkedIn Facebook Instagram X GitHub