Voice-Controlled Amenities for Enhanced Hotel Guest Experience
In the hospitality sector, delivering exceptional guest experiences is a top priority. One hotel chain recognized an opportunity to enhance its offerings through voice-enabled technology. They partnered with us to implement a wake word detection system and voice-activated concierge services. The goal was to elevate convenience and satisfaction by enabling guests to control room amenities like lighting, temperature, and entertainment via voice commands. This technical blog post will dive into the details of the wake word detection system developed by Rudder Analytics, exploring the approaches used to ensure accurate speech recognition across diverse acoustic environments, user voices, and speech patterns.
Wake Word Detection
Wake word detection, also known as keyword spotting, is a critical component of voice-enabled systems that allow users to activate and interact with devices or applications using predefined voice commands. This technology is crucial in various applications, including virtual assistants, smart home devices, and voice-controlled interfaces.
The primary objective of wake word detection is to continuously monitor audio streams for the presence of a specific wake word or phrase. After detecting the wake word, the system activates and listens for subsequent voice commands or queries. Effective wake word detection systems must balance accuracy, computational efficiency, and power consumption.
A brief overview of the process:
The process begins when the user speaks to the device/application. The words are captured as an audio input.
Next comes the feature extraction where specific characteristics are extracted from the sound of the user’s voice that will help recognize the wake word.
Now, the device/application turns these features into embedding representation, like a unique digital fingerprint that represents the wake word’s sound pattern.
This is where the pre-trained model comes into play. Before the device/application listens to the user, it is trained on many examples to learn what the wake word sounds like.
This model is fine-tuned with target keyword examples (the actual wake words it needs to listen for) and non-target examples (all the other words that aren’t the wake word).
The fine-tuned model then captures only the wake word while neglecting the other non-target words.
Challenges to Tackle
The main challenge was to develop a wake word detection system that accurately recognizes specific commands within a continuous audio stream. This task was complicated by the need for the system to perform reliably across various acoustic settings, from quiet rooms to those with background noise or echoes. Additionally, the system had to be versatile enough to recognize spoken commands by a wide array of users, each with their unique voice, accent, and speech pattern.
Crafting Our Solution
Few-Shot Transfer Learning Approach
Few-shot transfer learning is a technique that can enable machine learning models to quickly adapt to new tasks using only a limited number of examples. The approach builds upon extensive prior training on related but broad tasks, allowing models to leverage learned features and apply them to new, specific challenges with minimal additional input.
This strategy is particularly valuable in scenarios where data is scarce. By enhancing model adaptability and efficiency, this technique offers a realistic solution to data scarcity in natural language processing. The ability of few-shot transfer learning to empower machine learning models to generalize from limited data has significant practical applications, making it an increasingly popular research topic in the field of artificial intelligence.
Model Fine Tuning
1. Starting With a Foundation
Our system begins with a pre-trained multilingual embedding model. This is a base model that’s already been trained on a vast array of languages and sounds, giving it a broad understanding of speech patterns.
Pre-trained Multilingual Embedding Model
Our approach leveraged a Deep Neural Network (DNN)-based, pre-trained multilingual embedding model. This model was initially trained on 760 frequent words from nine languages, drawing from extensive datasets such as:
MLCommons Multilingual Spoken Words: Contains more than 340,000 keywords, totaling 23.4 million 1-second spoken examples (over 6,000 hours)
Common Voice Corpus: 9,283 recorded hours with demographic metadata like age, sex, and accent. The dataset consists of 7,335 validated hours in 60 languages.
Google Speech Commands for background noise samples: 8.17 GiB audio dataset of spoken words designed to help train and evaluate keyword spotting systems.
This rich training background laid a foundation for the system’s language and accent inclusivity.
2. Selective Hearing
The fine-tuning process involves teaching the model to focus on a small set of important sounds – the wake words. Fine-tuning the model for a new wake word using few-shot transfer learning is achieved by updating the model’s weights using a small dataset of audio recordings containing the new wake word.
With the hotel’s custom needs in mind, we fine-tuned the model with just five custom target keyword samples as training data. This method allowed us to fine-tune a five-shot keyword spotting context model, enabling the pre-trained model to generalize over new data categories swiftly.
3. Distinguishing the Target
It’s not just about knowing the wake word but also about knowing what it’s not. An unknown keywords dataset of 5,000 non-target keyword examples was used to maintain the ability of the few-shot model to distinguish between the target keyword and non-target keywords.
4. Tailored Adjustments
The pre-trained model was adjusted incrementally, learning to recognize the wake word more accurately from the examples provided. This involved tweaking the internal settings, or parameters, of the model to minimize errors. The fine-tuning process typically employs a variant of stochastic gradient descent (SGD) or other optimization algorithms.
5. Testing and Retesting
After each adjustment, the model was tested to see how well it can distinguish the wake word from other sounds. It’s a cycle of testing, learning, and improving.
6. Optimizing for Real World Use
During fine-tuning, the model was introduced to variations of the wake word as it might be spoken in different accents, pitches, or speech speeds, ensuring the model can recognize the wake word in diverse conditions. This was done by using techniques like data augmentation and noise addition.
7. Reducing False Triggers
A crucial part of fine-tuning is to reduce false positives—times when the device wakes up but shouldn’t. This involves adjusting the model so that it becomes more discerning and able to tell apart similar words or sounds from the actual wake word.
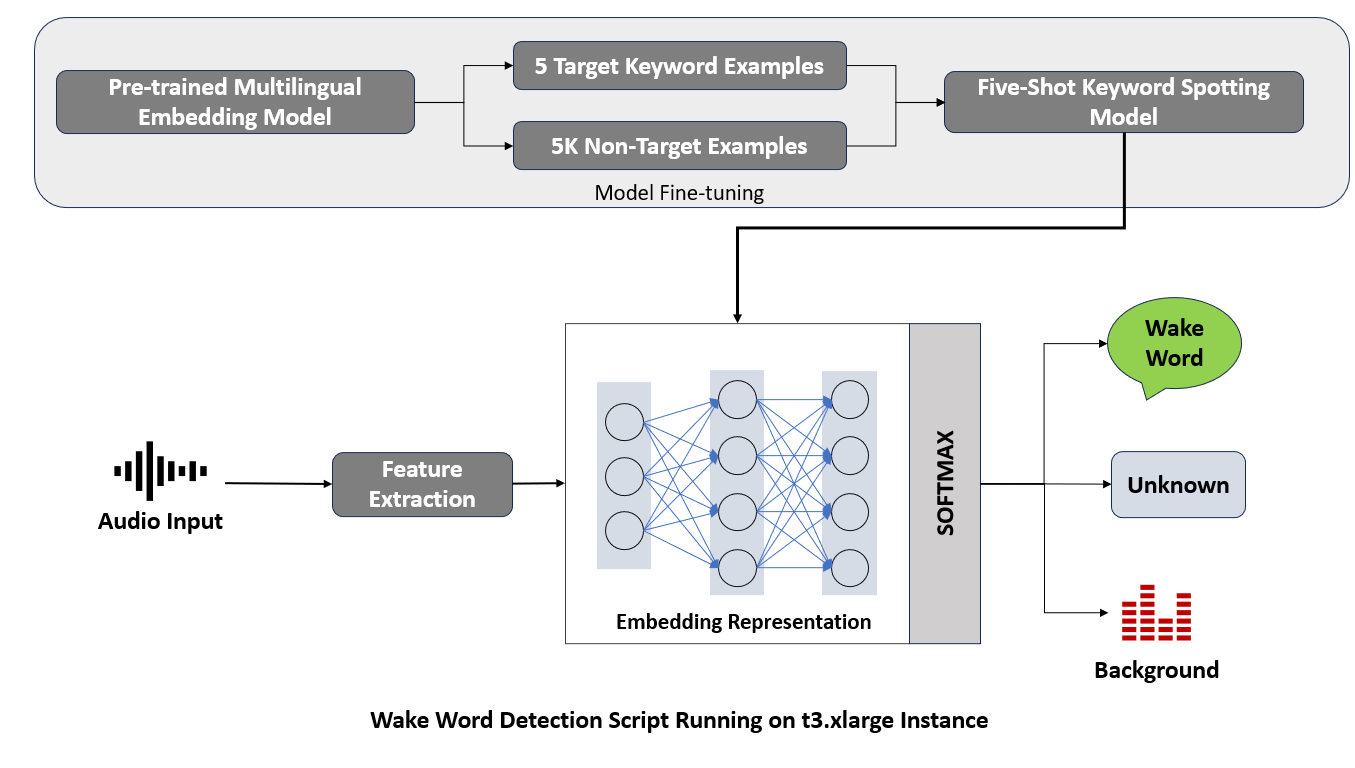
Fine-tuned Wake Word Detection Model
1. Audio Input and Feature Extraction
At the start of the wake word detection pipeline, audio input is received and passed through a feature extraction process. This step is crucial for transforming raw audio waveforms into a structured format that the neural network can interpret. Feature extraction algorithms focus on isolating the most relevant aspects of the audio signal, such as frequency and amplitude, which are informative of the content within the audio.
2. Neural Network and Embedding Representation
The extracted features are then input into a neural network, which acts as the engine of the wake word detection system. The network maps the features to an embedding space, where the learned representations are optimized to cluster target wake words close together while distancing them from non-target sounds and words.
3. The Softmax layer
The use of a softmax layer is standard in classification tasks. However, in the context of wake word detection, the softmax layer presents a unique challenge. It needs to classify inputs into one of three categories: the wake word, unknown words, or background noise. The softmax layer must be finely tuned to ensure that it can confidently distinguish between these categories, which is critical for reducing both false positives and negatives.
4. Real-time Processing
An efficient sliding window mechanism was implemented to enable the real-time analysis of continuous audio streams, ensuring prompt system responsiveness with minimal latency.
5. Deployment on a Cloud Instance
Once the model is trained and validated, it’s deployed to a cloud-based service running on a t3.xlarge instance. This selection of cloud computing resources ensures that the wake word detection script has access to high performance and scalability to handle real-time audio processing without significant latency.
Measurable Impact and Beyond
The implementation of this system had a clear impact, achieving an accuracy of 97% in wake word detection and a remarkable 99.9% uptime during stress testing and performance evaluations. This reliability ensured the system’s scalability and dependability, critical factors in a hotel environment where downtime can significantly affect guest satisfaction.
The most telling outcome was the 23% increase in guest satisfaction scores following the system’s implementation. This surge in guest approval underscored the system’s effectiveness in enhancing the overall stay experience, affirming the value of integrating AI and ML technologies in service-oriented industries.
Our wake word detection system ensured high accuracy, decreased the occurrence of false positives, and operated with reduced latency, facilitating immediate and correct command detection, and thereby considerably improving the overall user experience.
Conclusion
In wrapping up this project on voice-controlled hotel room amenities, it’s clear that our technical efforts and the application of AI and ML have significantly improved how customer service can be delivered. This work highlights the practical benefits of leveraging advanced technologies to make everyday interactions more user-friendly and efficient. At Rudder Analytics, our focus remains on exploring the potential of AI and ML to contribute to progress and achieve high standards in various fields.
Elevate your projects with our expertise in cutting-edge technology and innovation. Whether it’s advancing voice-controlled system capabilities or pioneering new tech frontiers, our team is ready to collaborate and drive success. Join us in shaping the future—explore our services, and let’s create something remarkable together. Connect with us today and take the first step towards transforming your ideas into reality.
Drop by and say hello! Website LinkedIn Facebook Instagram X GitHub